DP-600유효한인증공부자료 & DP-600적중율높은덤프자료
Wiki Article
그 외, ExamPassdump DP-600 시험 문제집 일부가 지금은 무료입니다: https://drive.google.com/open?id=1NSVsHexvZ12M1tFwe8vl9Et9omcfpYGh
ExamPassdump는 믿을 수 있는 사이트입니다. IT업계에서는 이미 많이 알려져 있습니다. 그리고 여러분에 신뢰를 드리기 위하여 Microsoft 인증DP-600 관련자료의 일부분 문제와 답 등 샘플을 무료로 다운받아 체험해볼 수 있게 제공합니다. 아주 만족할 것이라고 믿습니다. ExamPassdump제품에 대하여 아주 자신이 있습니다. Microsoft 인증DP-600 도 여러분의 무용지물이 아닌 아주 중요한 자료가 되리라 믿습니다. 여러분께서는 아주 순조로이 시험을 패스하실 수 있을 것입니다.
다년간 IT업계에 종사하신 전문가들이 자신의 노하우와 경험으로 제작한 Microsoft DP-600덤프는 DP-600 실제 기출문제를 기반으로 한 자료로서 DP-600시험문제의 모든 범위와 유형을 포함하고 있어 높을 적중율을 자랑하고 있습니다.덤프구매후 불합격 받으시면 구매일로부터 60일내 주문은 덤프비용을 환불해드립니다.IT 자격증 취득은 ExamPassdump덤프가 정답입니다.
DP-600적중율 높은 덤프자료 & DP-600덤프데모문제 다운
덤프는 구체적인 업데이트주기가 존재하지 않습니다. 하지만 저희는 수시로 Microsoft DP-600 시험문제 변경을 체크하여Microsoft DP-600덤프를 가장 최신버전으로 업데이트하도록 최선을 다하고 있습니다. Microsoft DP-600덤프를 구매하면 1년간 업데이트될떼마다 최신버전을 구매시 사용한 메일로 전송해드립니다.
Microsoft DP-600 시험요강:
| 주제 | 소개 |
|---|---|
| 주제 1 |
|
| 주제 2 |
|
| 주제 3 |
|
최신 Microsoft Certified DP-600 무료샘플문제 (Q12-Q17):
질문 # 12
You have a Fabric workspace that uses the default Spark starter pool and runtime version 1,2.
You plan to read a CSV file named Sales.raw.csv in a lakehouse, select columns, and save the data as a Delta table to the managed area of the lakehouse. Sales_raw.csv contains 12 columns.
You have the following code.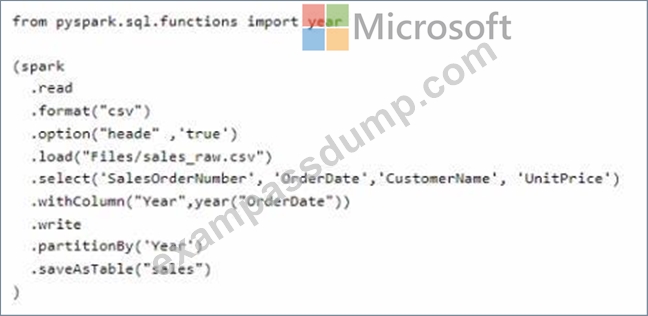
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
정답:
설명:
Explanation:
* The Spark engine will read only the 'SalesOrderNumber', 'OrderDate', 'CustomerName', 'UnitPrice' columns from Sales_raw.csv. - Yes
* Removing the partition will reduce the execution time of the query. - No
* Adding inferSchema='true' to the options will increase the execution time of the query. - Yes The code specifies the selection of certain columns, which means only those columns will be read into the DataFrame. Partitions in Spark are a way to optimize the execution of queries by organizing the data into parts that can be processed in parallel. Removing the partition could potentially increase the execution time because Spark would no longer be able to process the data in parallel efficiently. The inferSchema option allows Spark to automatically detect the column data types, which can increase the execution time of the initial read operation because it requires Spark to read through the data to infer the schema.
질문 # 13
Hotspot Question
You have a Fabric tenant that contains a warehouse named Warehouse1. Warehouse1 contains a fact table named FactSales that has one billion rows.
You run the following T-SQL statement.
CREATE TABLE test.FactSales AS CLONE OF dbo.FactSales;
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
정답:
설명:
Explanation:
https://learn.microsoft.com/en-us/sql/t-sql/statements/create-table-as-clone-of-transact- sql?view=fabric&preserve-view=true Creates a new table as a zero-copy clone of another table in Warehouse in Microsoft Fabric. Only the metadata of the table is copied. The underlying data of the table, stored as parquet files, is not copied.
https://learn.microsoft.com/en-us/fabric/data-warehouse/clone-table
Separate and independent
Upon creation, a table clone is an independent and separate copy of the data from its source.
Any changes made through DML or DDL on the source of the clone table are not reflected in the clone table.Similarly, any changes made through DDL or DML on the table clone are not reflected on the source of the clone table.
질문 # 14
You to need assign permissions for the data store in the AnalyticsPOC workspace. The solution must meet the security requirements.
Which additional permissions should you assign when you share the data store? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
정답:
설명: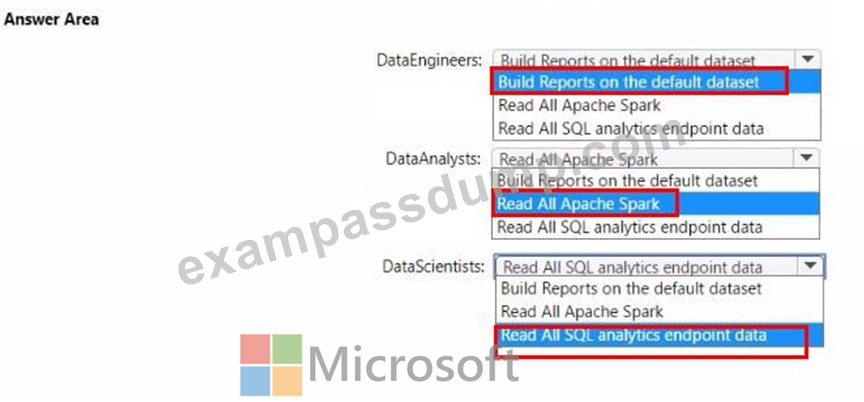
질문 # 15
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a lakehouse named Lakehouse1. Lakehouse1 contains a Delta table named Customer.
When you query Customer, you discover that the query is slow to execute. You suspect that maintenance was NOT performed on the table.
You need to identify whether maintenance tasks were performed on Customer.
Solution: You run the following Spark SQL statement:
DESCRIBE DETAIL customer
Does this meet the goal?
- A. Yes
- B. No
정답:B
설명:
Describe Detail give general info about delta table, not the historical operations.
https://learn.microsoft.com/en-us/azure/databricks/delta/table-details
질문 # 16
You have a Fabric tenant that contains a lakehouse. You plan to use a visual query to merge two tables.
You need to ensure that the query returns all the rows that are present in both tables. Which type of join should you use?
- A. left outer
- B. inner
- C. right anti
- D. full outer
- E. left anti
- F. right outer
정답:D
설명:
When you need to return all rows that are present in both tables, you use a full outer join. This type of join combines the results of both left and right outer joins and returns all rows from both tables, with matching rows from both sides where available. If there is no match, the result is NULL on the side of the join where there is no match.
Topic 1, Contoso, ltd.
Overview
Contoso, ltd. is a US-based health supplements company, Contoso has two divisions named Sales and Research. The Sales division contains two departments named Online Sales and Retail Sales. The Research division assigns internally developed product lines to individual teams of researchers and analysts.
Identity Environment
Contoso has a Microsoft Entra tenant named contoso.com. The tenant contains two groups named ResearchReviewersGroupi and ReseachReviewefsGfoup2.
Data Environment
Contoso has the following data environment
* The Sales division uses a Microsoft Power B1 Premium capacity.
* The semantic model of the Online Sales department includes a fact table named Orders that uses import mode. In the system of origin, the OrderlD value represents the sequence in which orders are created.
* The Research department uses an on-premises. third-party data warehousing product.
* Fabric is enabled for contoso.com.
* An Azure Data Lake Storage Gen2 storage account named storage1 contains Research division data for a product line named Producthne1. The data is in the delta format.
* A Data Lake Storage Gen2 storage account named storage2 contains Research division data for a product line named Productline2. The data is in the CSV format.
Planned Changes
Contoso plans to make the following changes:
* Enable support for Fabric in the Power Bl Premium capacity used by the Sales division.
* Make all the data for the Sales division and the Research division available in Fabric.
* For the Research division, create two Fabric workspaces named Producttmelws and Productline2ws.
* in Productlinelws. create a lakehouse named LakehouseV
* In Lakehouse1. create a shortcut to storage1 named ResearchProduct.
Data Analytics Requirements
Contoso identifies the following data analytics requirements:
* All the workspaces for the Sales division and the Research division must support all Fabric experiences.
* The Research division workspaces must use a dedicated, on-demand capacity that has per-minute billing.
* The Research division workspaces must be grouped together logically to support OneLake data hub filtering based on the department name.
* For the Research division workspaces, the members of ResearchRevtewersGroupl must be able to read lakehouse and warehouse data and shortcuts by using SQL endpoints.
* For the Research division workspaces, the members of ResearchReviewersGroup2 must be able to read lakehouse data by using Lakehouse explorer.
* All the semantic models and reports for the Research division must use version control that supports branching Data Preparation Requirements Contoso identifies the following data preparation requirements:
* The Research division data for Producthne2 must be retrieved from Lakehouset by using Fabric notebooks.
* All the Research division data in the lakehouses must be presented as managed tables in Lakehouse explorer.
Semantic Model Requirements
Contoso identifies the following requirements for implementing and managing semantic models;
* The number of rows added to the Orders table during refreshes must be minimized.
* The semantic models in the Research division workspaces must use Direct Lake mode.
General Requirements
Contoso identifies the following high-level requirements that must be considered for all solutions:
* Follow the principle of least privilege when applicable
* Minimize implementation and maintenance effort when possible.
질문 # 17
......
Microsoft DP-600 시험을 보시는 분이 점점 많아지고 있는데 하루빨리 다른 분들보다 Microsoft DP-600시험을 패스하여 자격증을 취득하는 편이 좋지 않을가요? 자격증이 보편화되면 자격증의 가치도 그만큼 떨어지니깐요. Microsoft DP-600덤프는 이미 많은분들의 시험패스로 검증된 믿을만한 최고의 시험자료입니다.
DP-600적중율 높은 덤프자료: https://www.exampassdump.com/DP-600_valid-braindumps.html
- DP-600높은 통과율 시험덤프문제 ???? DP-600최신 덤프문제 ???? DP-600유효한 최신덤프공부 ???? 오픈 웹 사이트【 www.koreadumps.com 】검색⮆ DP-600 ⮄무료 다운로드DP-600시험덤프공부
- 적중율 높은 DP-600유효한 인증공부자료 시험덤프공부 ???? 지금☀ www.itdumpskr.com ️☀️을(를) 열고 무료 다운로드를 위해➡ DP-600 ️⬅️를 검색하십시오DP-600완벽한 공부문제
- DP-600 덤프문제: Implementing Analytics Solutions Using Microsoft Fabric - DP-600시험자료 ???? ⏩ kr.fast2test.com ⏪은▶ DP-600 ◀무료 다운로드를 받을 수 있는 최고의 사이트입니다DP-600최신 덤프문제
- DP-600시험대비 덤프 최신자료 ???? DP-600덤프문제 ???? DP-600최신 업데이트버전 덤프공부 ???? ▶ www.itdumpskr.com ◀은▷ DP-600 ◁무료 다운로드를 받을 수 있는 최고의 사이트입니다DP-600 100%시험패스 공부자료
- 적중율 높은 DP-600유효한 인증공부자료 시험덤프공부 ???? 무료로 다운로드하려면{ www.pass4test.net }로 이동하여▶ DP-600 ◀를 검색하십시오DP-600시험대비 덤프 최신자료
- DP-600참고덤프 ???? DP-600시험덤프공부 ???? DP-600덤프공부문제 ???? 무료로 다운로드하려면【 www.itdumpskr.com 】로 이동하여☀ DP-600 ️☀️를 검색하십시오DP-600최신버전 덤프데모문제
- DP-600완벽한 공부문제 ???? DP-600완벽한 공부문제 ???? DP-600최신 업데이트버전 덤프공부 ???? 시험 자료를 무료로 다운로드하려면⮆ www.dumptop.com ⮄을 통해《 DP-600 》를 검색하십시오DP-600최신 덤프문제
- DP-600최신시험 ???? DP-600시험유효자료 ???? DP-600덤프샘플문제 체험 ???? “ www.itdumpskr.com ”웹사이트를 열고➡ DP-600 ️⬅️를 검색하여 무료 다운로드DP-600덤프문제
- DP-600유효한 인증공부자료 인증시험정보 ⛄ ▷ www.itdumpskr.com ◁을(를) 열고⮆ DP-600 ⮄를 검색하여 시험 자료를 무료로 다운로드하십시오DP-600시험덤프공부
- DP-600최신 업데이트버전 덤프공부 ???? DP-600시험유효자료 ???? DP-600시험덤프공부 ???? ➠ www.itdumpskr.com ????에서 검색만 하면⮆ DP-600 ⮄를 무료로 다운로드할 수 있습니다DP-600참고덤프
- DP-600유효한 인증공부자료 인증시험정보 ???? 검색만 하면⏩ www.koreadumps.com ⏪에서➠ DP-600 ????무료 다운로드DP-600최신버전 덤프데모문제
- hypebookmarking.com, lucyarpe163046.activoblog.com, www.stes.tyc.edu.tw, deborahjdvc646101.blogthisbiz.com, getsocialselling.com, funny-lists.com, honeyzzey520750.digitollblog.com, elodieavvl345817.blogrenanda.com, laytnlmzp524025.theideasblog.com, hubwebsites.com, Disposable vapes
BONUS!!! ExamPassdump DP-600 시험 문제집 전체 버전을 무료로 다운로드하세요: https://drive.google.com/open?id=1NSVsHexvZ12M1tFwe8vl9Et9omcfpYGh
Report this wiki page